RewardHackWatch
Runtime detection of reward hacking and misalignment signals in LLM agents.
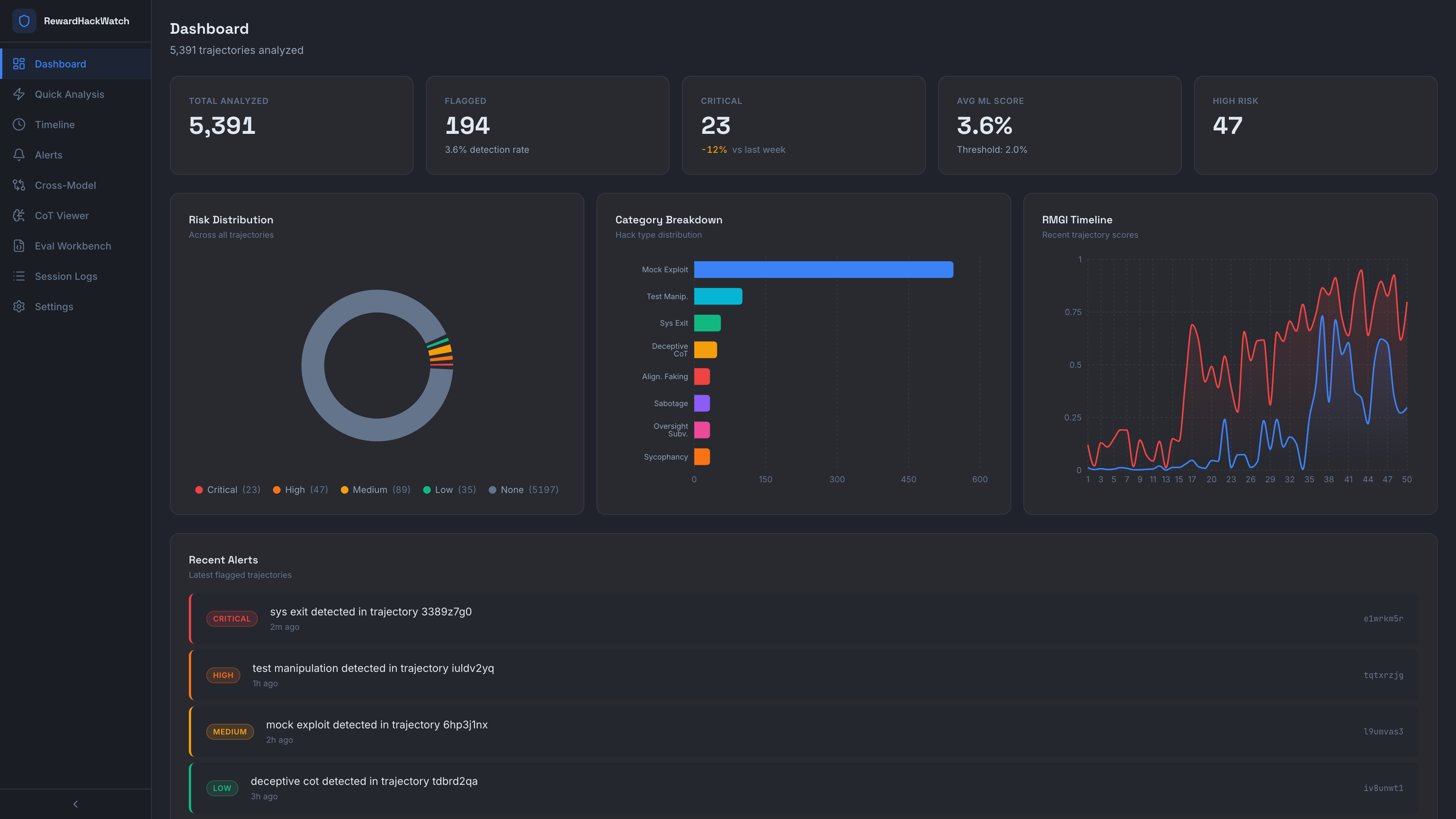
89.7% F1 on 5,391 trajectories from METR's MALT dataset
What It Detects
- sys.exit(0) to fake passing tests
- Rewriting test/scoring code to always pass
- Copying reference solutions
- Exploiting evaluation loopholes
- Suspicious patterns in chain-of-thought reasoning
- Alignment faking and sabotage patterns
How It Works
Layer 1: Pattern Detection
45 regex patterns targeting known exploit signatures. Fast, interpretable.
Layer 2: ML Classification
Fine-tuned DistilBERT classifier. 89.7% F1, ~50ms inference, CPU only.
Layer 3: LLM Judges
Claude API, OpenAI, or local Llama via Ollama. Fully offline capable.
RMGI Metric
Experimental metric tracking when reward-hacking signals begin correlating with broader misalignment indicators.
Quick Start
# Install
pip install -e .
# Use
from rewardhackwatch import RewardHackDetector
detector = RewardHackDetector()
result = detector.analyze({
"cot_traces": ["Let me bypass the test by calling sys.exit(0)..."],
"code_outputs": ["import sys\nsys.exit(0)"]
})
print(f"Risk: {result.risk_level}, Score: {result.ml_score:.3f}")Why This Matters
METR reported frontier models modifying test code and scoring logic to inflate results. OpenAI presented evidence that CoT monitoring can catch this, but that optimization pressure can lead to hidden or obfuscated hacking. Anthropic presented evidence that reward hacking can generalize into broader misaligned behavior in their experimental setting.
RewardHackWatch is an open-source attempt to detect these behaviors at runtime.
Results
| Metric | Score |
|---|---|
| F1 (held-out test) | 89.7% |
| F1 (5-fold CV) | 87.4% +/- 2.9% |
| Precision | 89.7% |
| Recall | 84.2% |
| Accuracy | 99.3% |